繁體中文
简体中文
Home
- Movie Data Crawler (MDC) is a powerful software tool
- Designed for organizing and scraping local movie or series files, obtaining movie or series metadata and downloading covers from the Internet
- MDC has 2 parts: web user panel and local client
User Panel
- Account Management: Provide user registration and login functions
- Cloud Configuration Management: Used to manage configuration settings for cloud scraping
- Device Management: Used to view devices used to manage login accounts
Native client
✅ OpenAI large model translation access support
✅ Supports Windows, Linux, Docker, MacOS X86 & ARM
✅ Cloud configuration synchronization: The client can synchronize the cloud configuration on the web page, and organize and scrape local movies based on the cloud configuration.
✅ Metadata acquisition and cover download: According to the cloud configuration, metadata scraping and cover download of local videos are performed
✅ Multi-Client Support: Supports using multiple cloud configuration instances on multiple local clients using the same account
Contact us
Use tutorial
- This program and website** do not provide any video download method and are only used for personal file organization**
1. Download and execute the program
- Upon first opening, you can select the language in the
Languagefield:English. - Except for Windows systems, please read [How to use each client] (/clients.html) before downloading
- It is strongly recommended to install the
Chromebrowser, as MDC relies onChrometo improve the success rate of scraping.
2. Register an account and log in
- Register an account at the [User Panel] (https://user.mvdc.top) on the web page
- Click
Loginin Client
- You can personalize [settings] after logging in on the web (https://user.mvdc.top/configuration/general). New users are recommended to use the current default settings.
- Cloud configuration supports multiple configuration instances, and multiple cloud configuration instances can be added to handle different types of videos
- Each account can log in to up to 3 devices, and each of the two configurations can have up to 6 cloud configuration instances. *(Optional) If you use it frequently or have requirements for accurate data, it is recommended that you apply for TMDB API KEY and fill it in the cloud settings
3. Subscribe
- On the Activate Subscription page, select the subscription plan that suits you
- Subscription will be automatically activated after payment is completed
- Multiple payment methods are supported
4. Local Configuration
- Set the scraping folder and output folder in the
Local Configurationpage
- By default, the input folder is the directory where the program is located, and the output folder is the newly created
outputfolder in the directory where the program is located.
External subtitle file
If the prefix of the subtitle file name in the 'scraping directory' is the same as the prefix of the video file, it will be automatically moved to the same directory as the video in subsequent processing, and the 'subtitles' tag will be added to the NFO metadata file label. And add a floating watermark to the cover (can be turned on or off in the web cloud settings page)
5. According to the File Naming Rules, click the corresponding Scraping Type in the lower right corner of the Local Configuration page
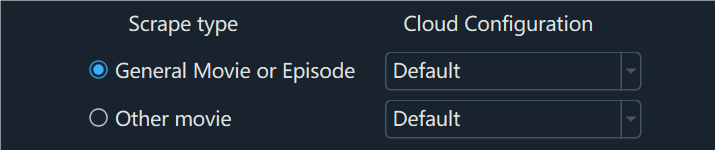
- Please perform name extraction to check whether it meets expectations before processing the video
- If you find that the extracted name does not match the expected video, please rename it manually.
6. Start
- If you have modified the cloud configuration on the web page after logging in on the client, please click
Synchronizeon the clientConfigurationpage before clickingStartbefore running the configuration
Tips
- Supports dragging multiple or single files into the MDC window for scraping.
- When dragging a single file into the MDC window, you can customize the scraping name.
- Videos that fail to be processed will be recorded, and a
failed_list.txtfailure list file will be generated in the directory where the program is located, which can be removed in the local configuration page.
7. Ending
- The output folder can be imported into media managers such as Emby, Jellyfin, Plex, etc. to manage videos
Access program log
.mdc/logs in the directory where the system user is located